In inexact line search (a numerical optimisation technique) the step length (or learning rate) must be decided. In connection to that the Wolfe conditions are central. Here I will give an example showing why they are useful. More on this topic can be read elsewhere, e.g. in the book of Nocedal and Wright (2006), “Numerical Optimization”, Springer.
Wolfe conditions
The Wolfe conditions consists of the sufficient decrease condition (SDC) and curvature condition (CC):
\[\begin{align*} f(x_k + \alpha_k p_k) &\leq f(x_k) + c_1 \alpha_k \nabla f_k^\intercal p_k \tag{SDC}\\ \nabla f(x_k + \alpha_k p_k)^\intercal p_k &\geq c_2 \nabla f_k^\intercal p_k, \tag{CC} \end{align*}\] with \(0 < c_1 < c_2 < 1\).
The strong Wolfe conditions are:
\[\begin{align*} f(x_k + \alpha_k p_k) &\leq f(x_k) + c_1 \alpha_k \nabla f_k^\intercal p_k, \tag{SDC} \\ |\nabla f(x_k + \alpha_k p_k)^\intercal p_k| &\leq c_2 |\nabla f_k^\intercal p_k|, \tag{CC'} \end{align*}\] with \(0 < c_1 < c_2 < 1\).
Example
We use the Rosenbrock function to illustrate these conditions when choosing step length. We use a classic version, namely \[ f(x, y) = (1 - x)^2 + 100(y - x^2)^2 \] Its global minimum is at \((1, 1)\) and the gradient is \[ \nabla f(x, y) = \left( -2 \left( 1 - x\right) - 400 x \left( y - x ^{2}\right) , 200 \left( y - x ^{2}\right) \right) . \]
A few illustrations of the function \(f\) (the global minimum marked with a red cross):
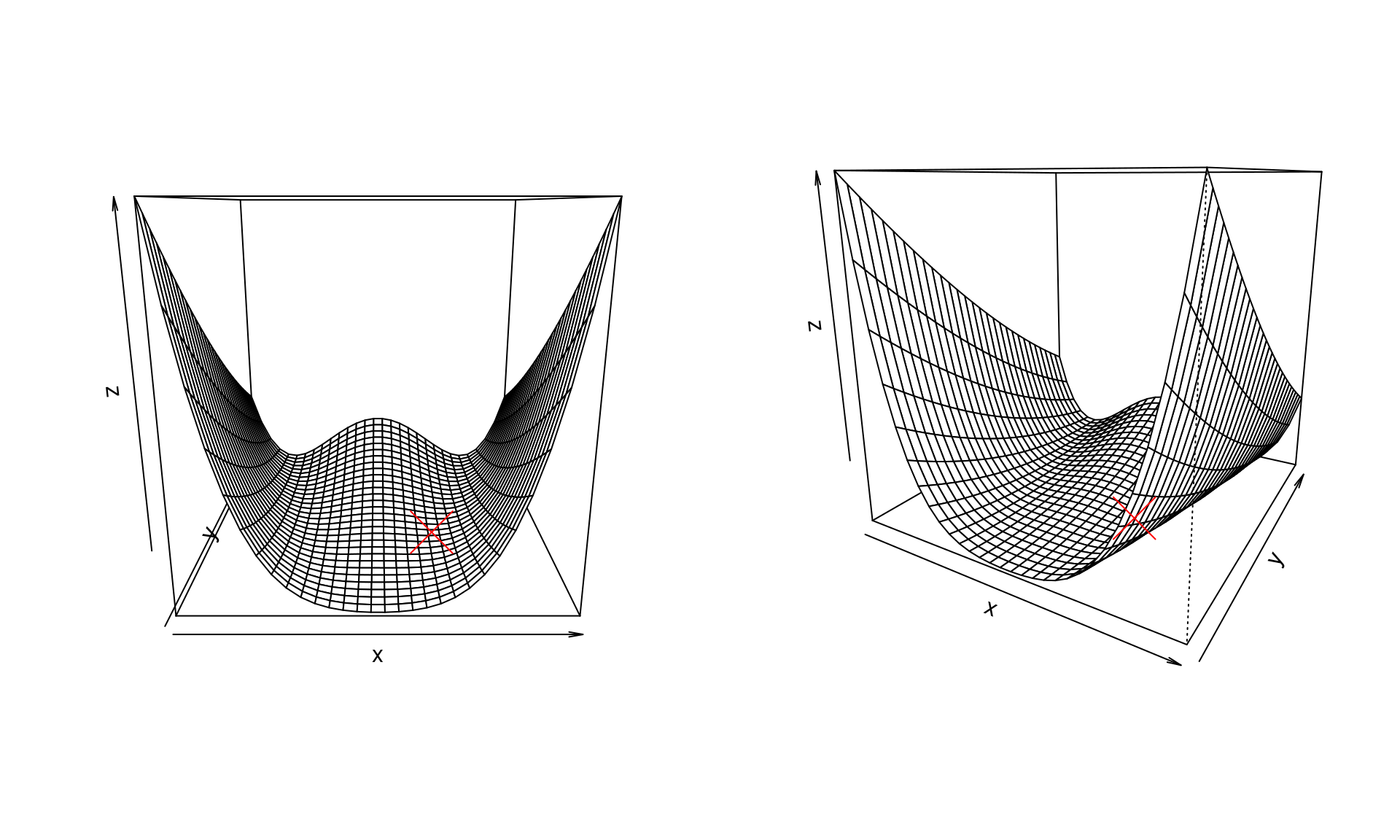
Let \(z = (x, y)\) and \(z_k = (x_k, y_k)\), and further \(f(z) = f(x, y)\) for easier notation. The line search is then \[ z_{k+1} = z_k + \alpha_k p_k \] for direction \(p_k\) and step length \(\alpha_k\). In determining the step length the function \[ \Phi(\alpha) = f(z_k + \alpha p_k) \] is often used. It tells us the value of the function we are minimising for any given step length \(\alpha\). Recall that the current position is \(z_k\) and the direction \(p_k\) is chosen. The only thing left to choose is \(\alpha\). So to make that more clear, we refer to \(\Phi(\alpha)\) instead of \(f(z_k + \alpha p_k)\).
The aim is that \(f(z_k + \alpha p_k) < f(z_k)\), and if the direction chosen is a descent direction (e.g. the negative gradient), then for sufficiently small \(\alpha\) this will be possible. But just using \(f(z_k + \alpha p_k) < f(z_k)\) as a criteria is not sufficient to ensure convergence, which is why the Wolfe conditions are used.
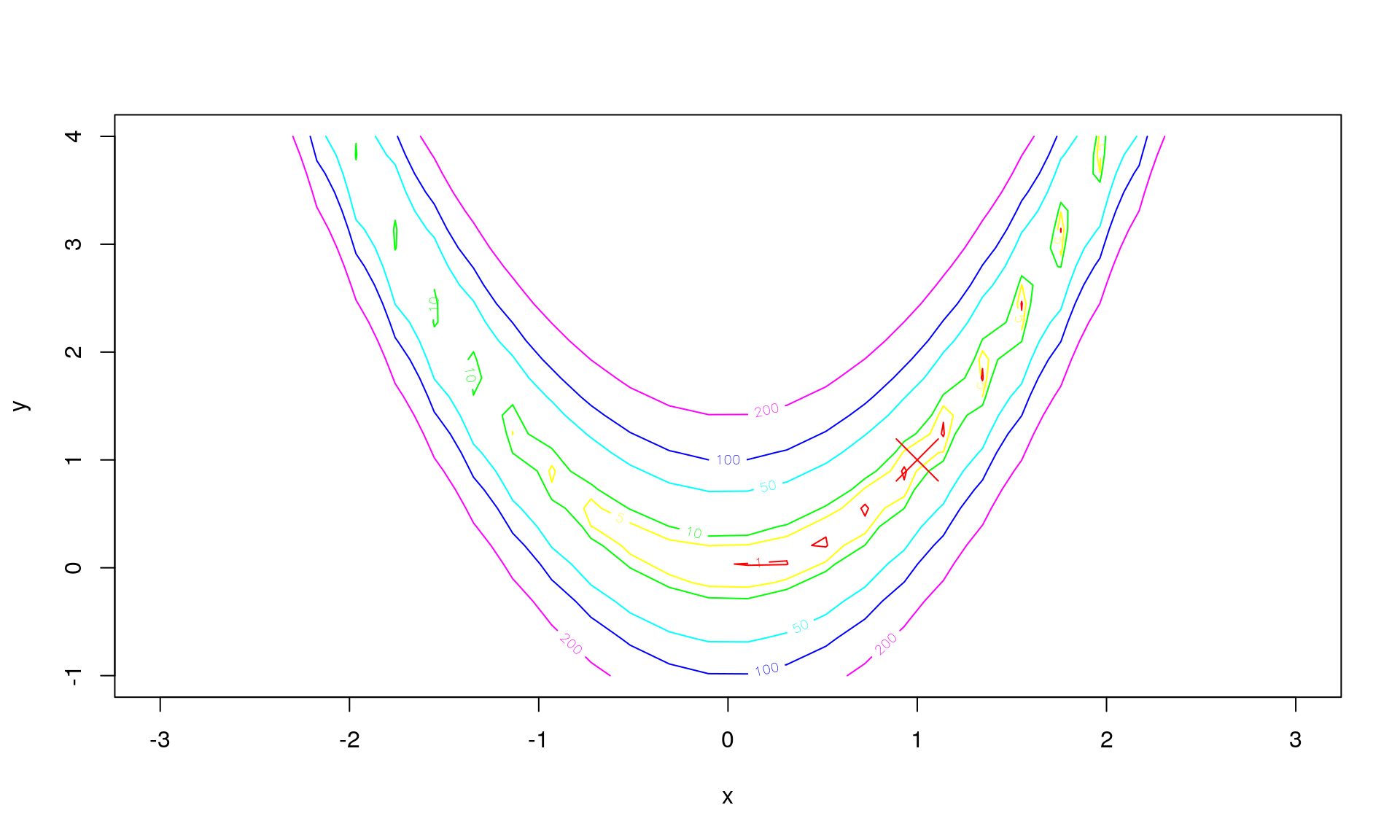
Now, say we start the line search at \[ z_0 = (x_0, y_0) = (-2.2, 3) , \] then the gradient at that point is \[ \nabla f_0 = \nabla f(z) \rvert_{z = z_0} = (-1625.6, -368) . \]
Say we to a line search from \(z_0 = (x_0, y_0)\) in the direction of the negative gradient given by \[ p_0 = (1625.6, 368) . \]
In \(z_0 = (x_0, y_0)\) we have that \[ \Phi(\alpha) = f(z_0 + \alpha p_0) . \]
Note that for \(\alpha = 1\) then \[ z_0 + \alpha p_0 = ((-2.2) + (1625.6), (3) + (368)) = (1623.4, 371) , \] so instead smaller values of \(\alpha\) are tried.
The path \(z_0 + \alpha p_0\) for \(\alpha\) between \(0\) and \(0.003\) (chosen to make this example illustrative) is then:
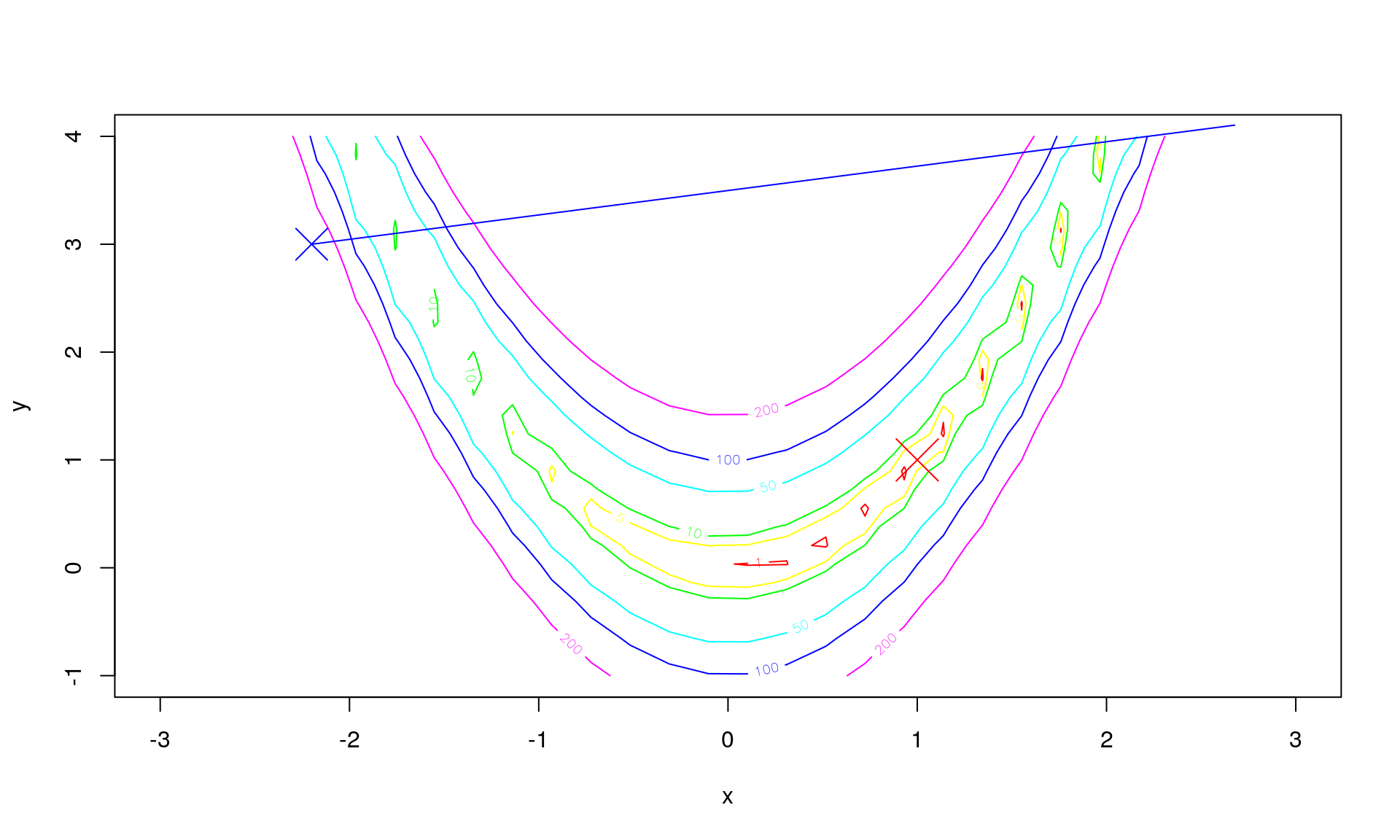
This can instead be shown by visualising \(\Phi(\alpha)\) instead as this is a univariate function, and \(f\) can be difficult/impossible to visualise directly as in this example. For this example, \(\Phi(\alpha)\) looks like this:
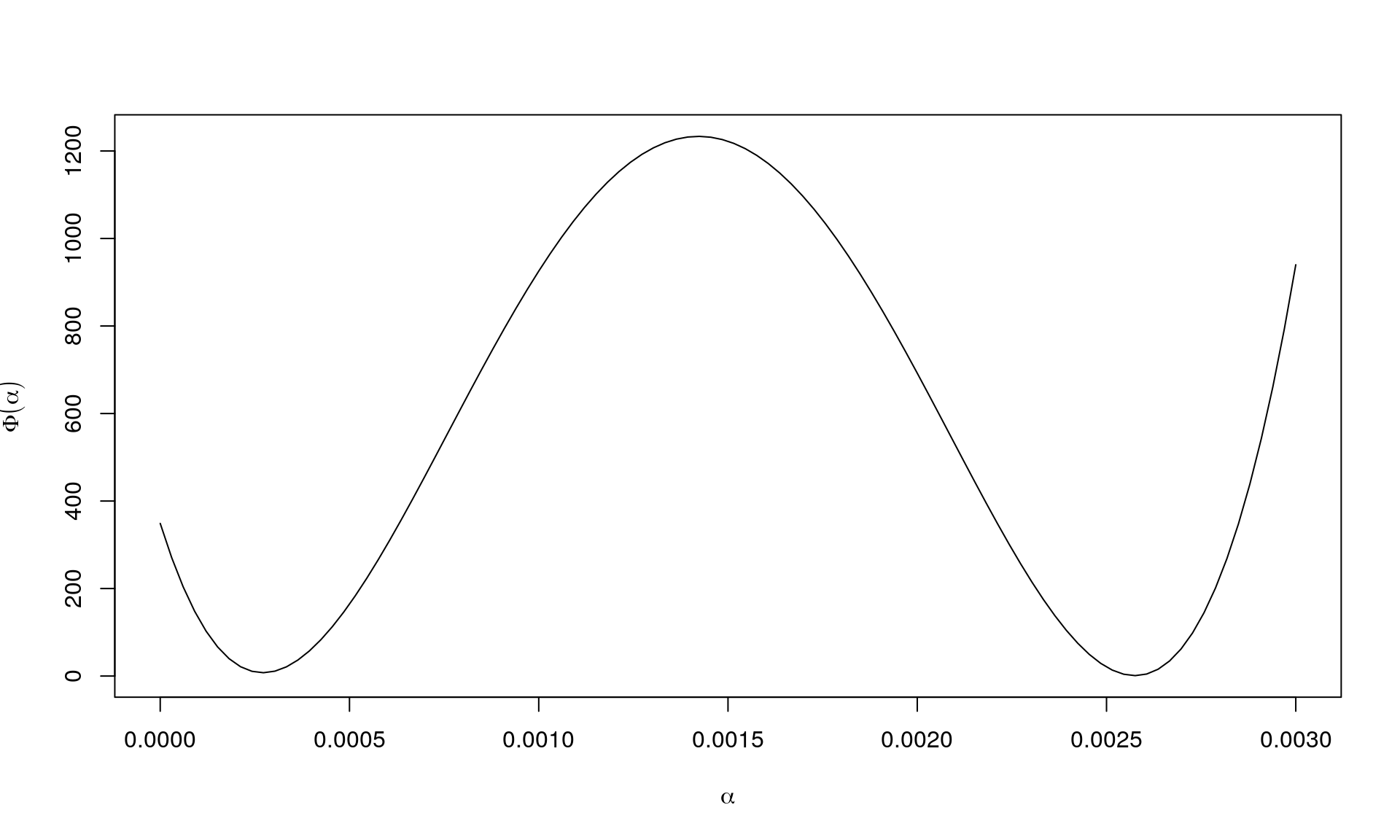
As seen, if \(\alpha\) is sufficiently small, then we move to a position with a smaller value for \(f\). But we can also end up in a place with a higher value (although we are moving in the descent direction).
The sufficient decrease condition
We now consider the Wolfe conditions. The SDC (sufficient decrease condition) is \[ \Phi(\alpha) = f(z_k + \alpha p_k) \leq f(z_k) + c_1 \alpha \nabla f_k^\intercal p_k \tag{SDC} \] with \(0 < c_1 < 1\). Let us disect this condition.
First, we focus on \(\nabla f_k^\intercal p_k\). Note that \(\nabla f_k^\intercal p_k = p_k \cdot \nabla f_k = \| p_k \| \| \nabla f_x \| \cos (\theta)\) (the latter equality in an Euclidian setting). What do we know about \(\theta\)? We require that \(p_k\) is a descent direction (“point in the same way as the negative gradient, \(-\nabla f_k\)”) and thus the angle between \(p_k\) and the negative gradient, \(-\nabla f_k\), is \((-\pi/2, \pi/2)\).
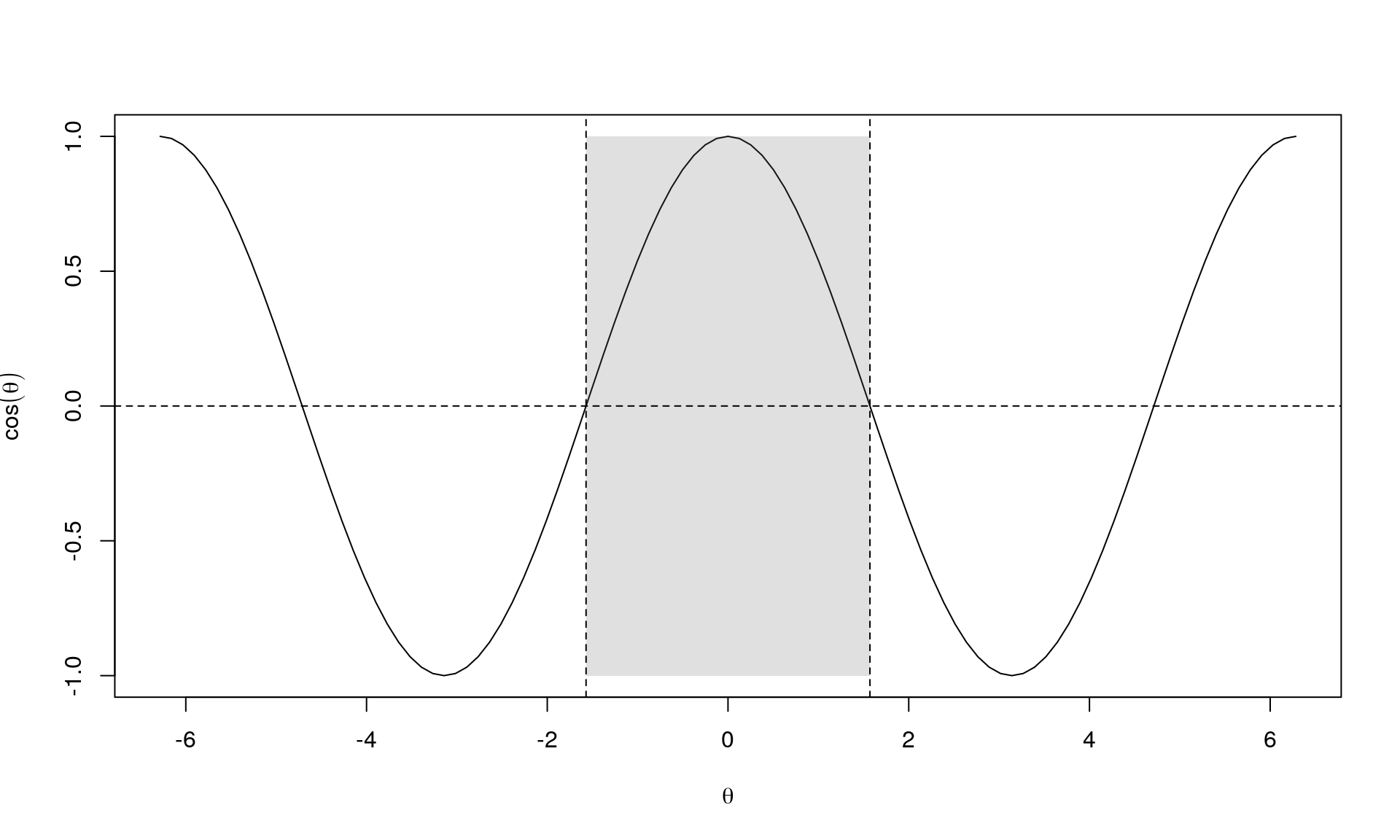
Instead of the negative gradient, we consider the gradient. So multiplying with \(-1\) means that \(\nabla f_k^\intercal p_k < 0\).
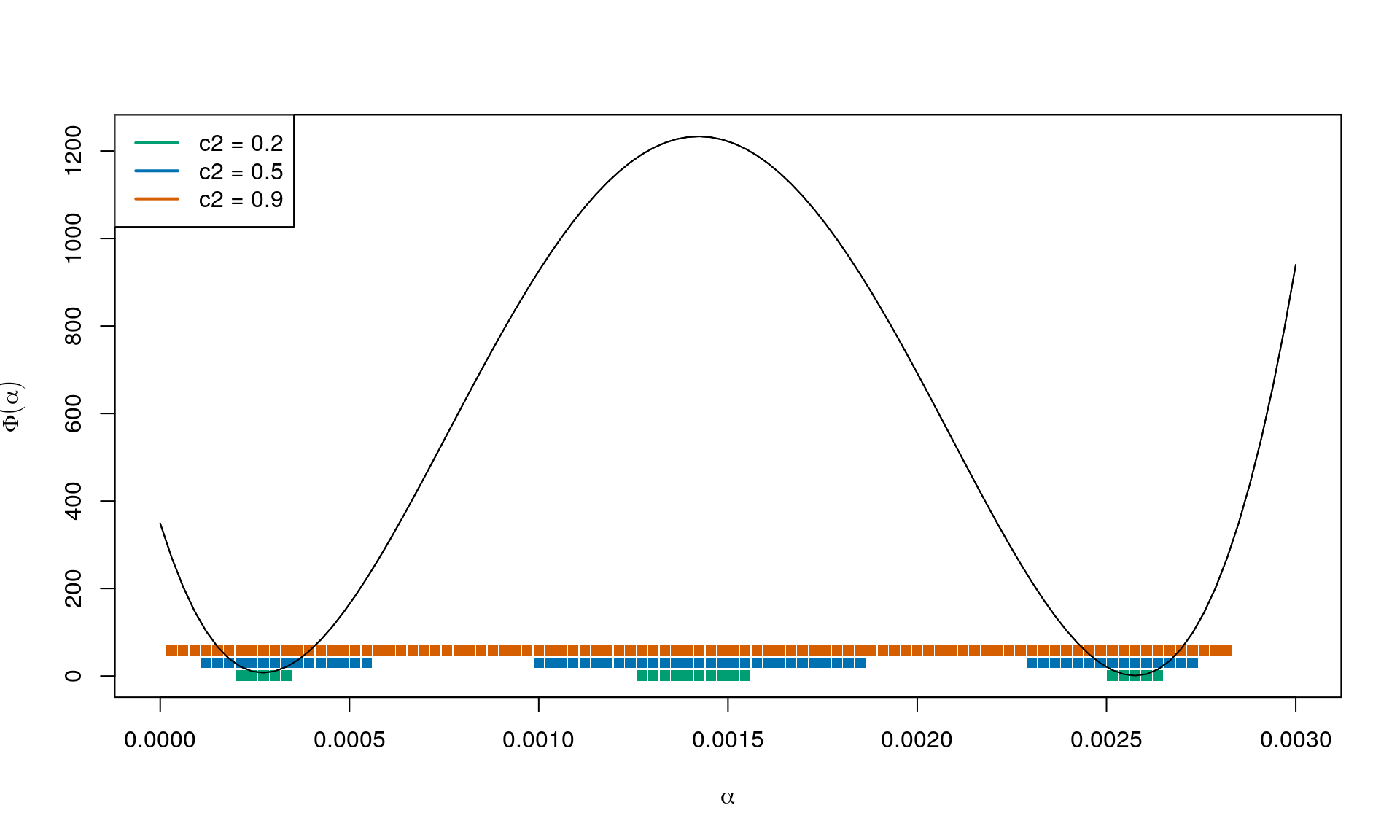
Further, \(f(z_k)\) is a value in \(\mathbb{R}\). And as \(c_1 > 0\), \(\alpha > 0\) and \(\nabla f_k^\intercal p_k < 0\) we have that \(c_1 \nabla f_k^\intercal p_k < 0\). In other words, the condition can be written as \[ \Phi(\alpha) \leq \beta_0 + \alpha \beta_1 \] where \(\beta_0 = f(z_k)\) and \(\beta_1 = c_1 \nabla f_k^\intercal p_k < 0\). So a stright line with negative slope.
In this case, \(\beta_0 = f(z_0) = 348.8\) and \(\beta_1 = c_1 \nabla f_k^\intercal p_k\) (using \(p_k = -\nabla f_k\)). See below for some choices of \(c_1\):
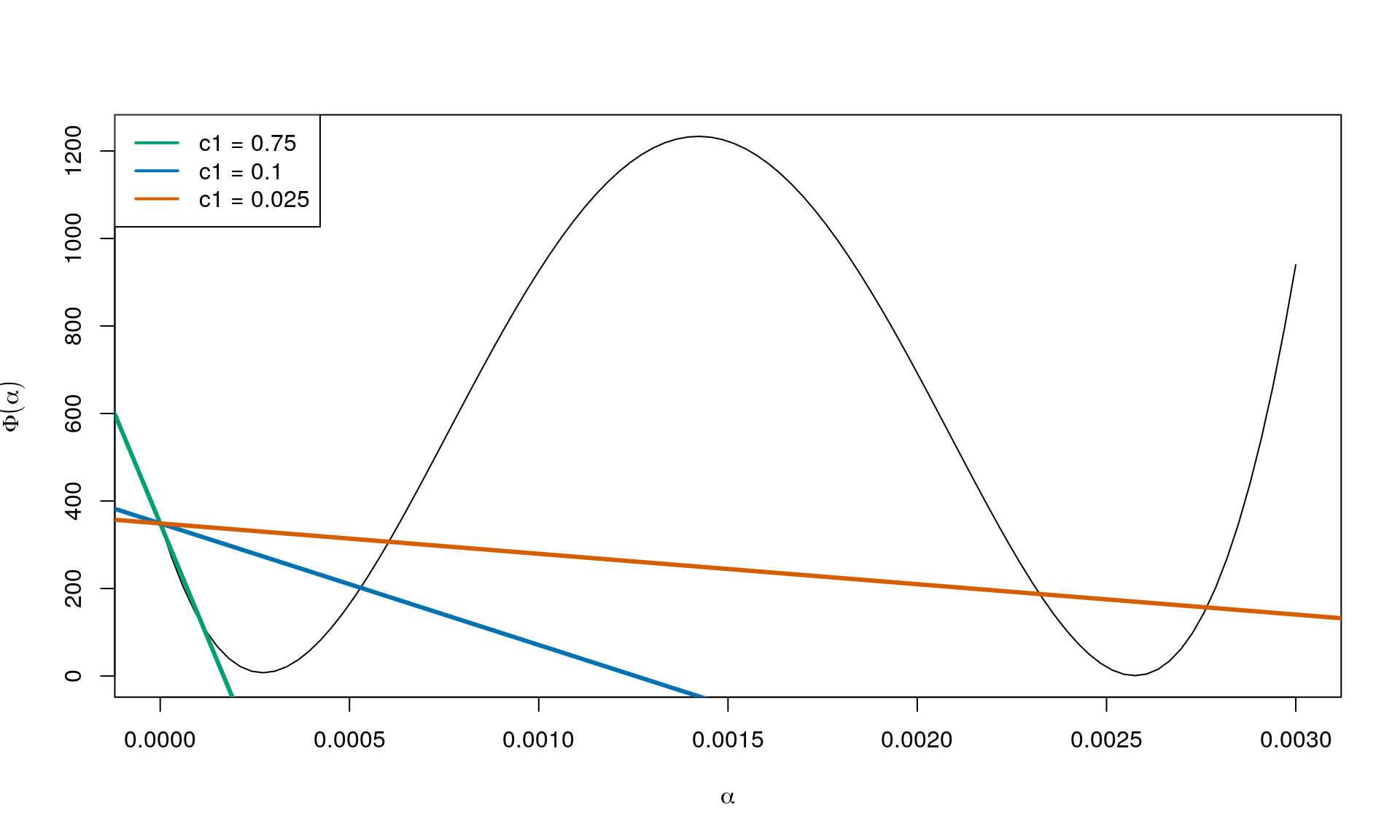
In other words, varying \(c_1\) from \(0\) to \(1\) gives straight lines from \(\Phi(\alpha) = f(z_k)\) for \(c_1 = 0\) to \(\Phi(\alpha) = f(z_k) + \alpha \nabla f_k^\intercal p_k\) for \(c_1 = 1\), where the latter corresponds to the tangent of \(\Phi(\alpha)\) at \(\alpha = 0\).
To see this note that at \(\alpha = 0\), the tangent to \(\Phi(\alpha)\) is \(c_1 \nabla f_k^\intercal p_k\). This should be the same as the directional derivative of the objective function \(f\) in the direction of \(p_k\). Which exactly happens for \(c_1 = 1\).
So the factor \(\nabla f_k^\intercal p_k\) makes it possible to go from the extreme cases with a horizontal line to that of the directional derivative of the objective function \(f\) in the direction of \(p_k\).
The curvature condition
The curvature condition (CC) is \[ \nabla f(z_k + \alpha_k p_k)^\intercal p_k \geq c_2 \nabla f_k^\intercal p_k \tag{CC} . \]
We are in \(z_k\) and looking in direction \(p_k\) which is a descent direction. We know from before that \(\nabla f_k^\intercal p_k < 0\), so it goes downhill from where we are now. We are looking for a critical point \(z^*\) such that \(\nabla f(z^*) = 0\). So at the next point \(z_{k+1} = z_k + \alpha_k p_k\) we think the gradient should be less negative than it is now; still looking in direction \(p_k\).
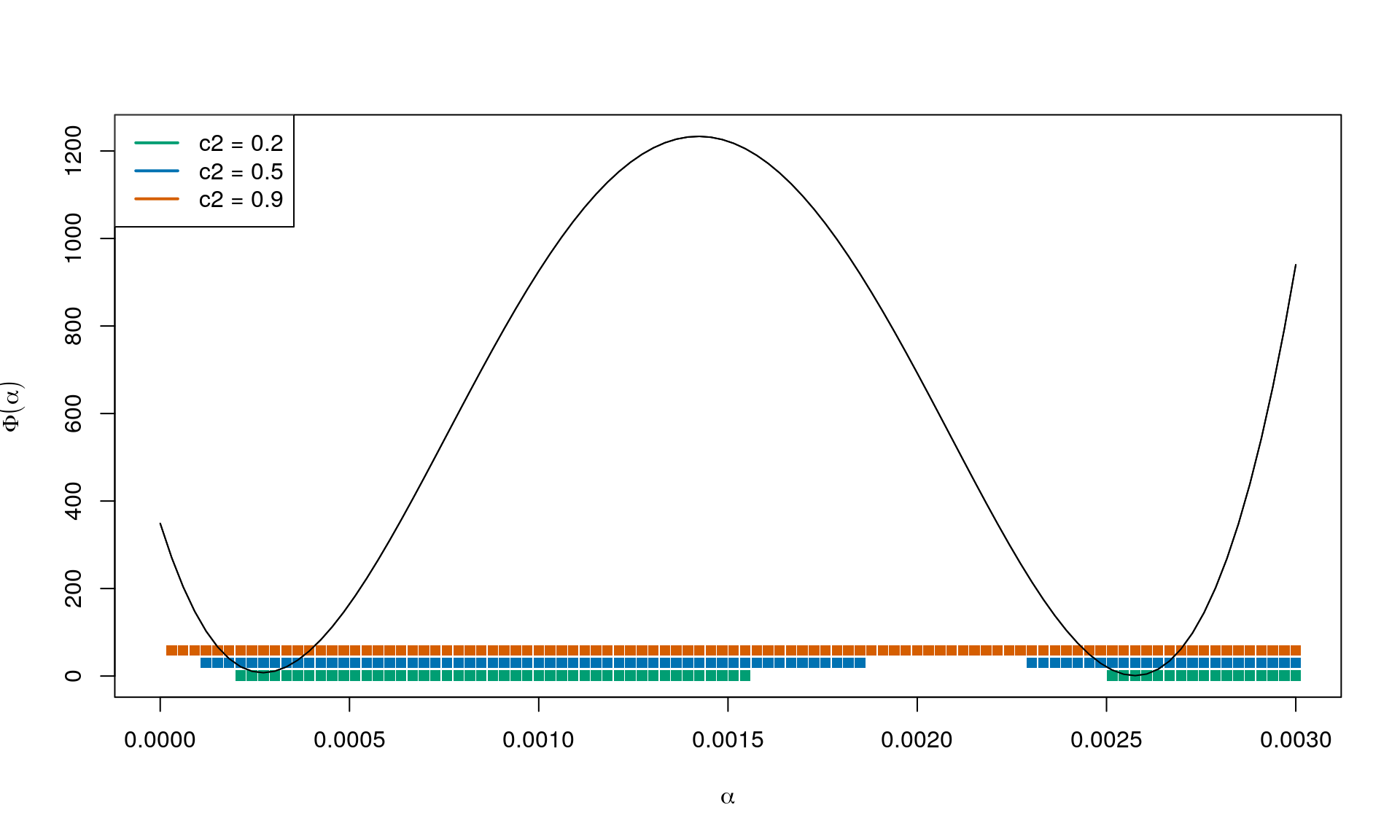
So the directional derivative at the next iterate continuing in the same direction as got us here has to be greater than \(c_2 \nabla f_k^\intercal p_k\), with \(c_2\) controlling the expression to range from 0 to \(\nabla f_k^\intercal p_k\), i.e. the directional derivative where we are standing now (\(z_k\)).
Combining
Result for \(c_1 = 0.025\) and \(c_2 = 0.2\):
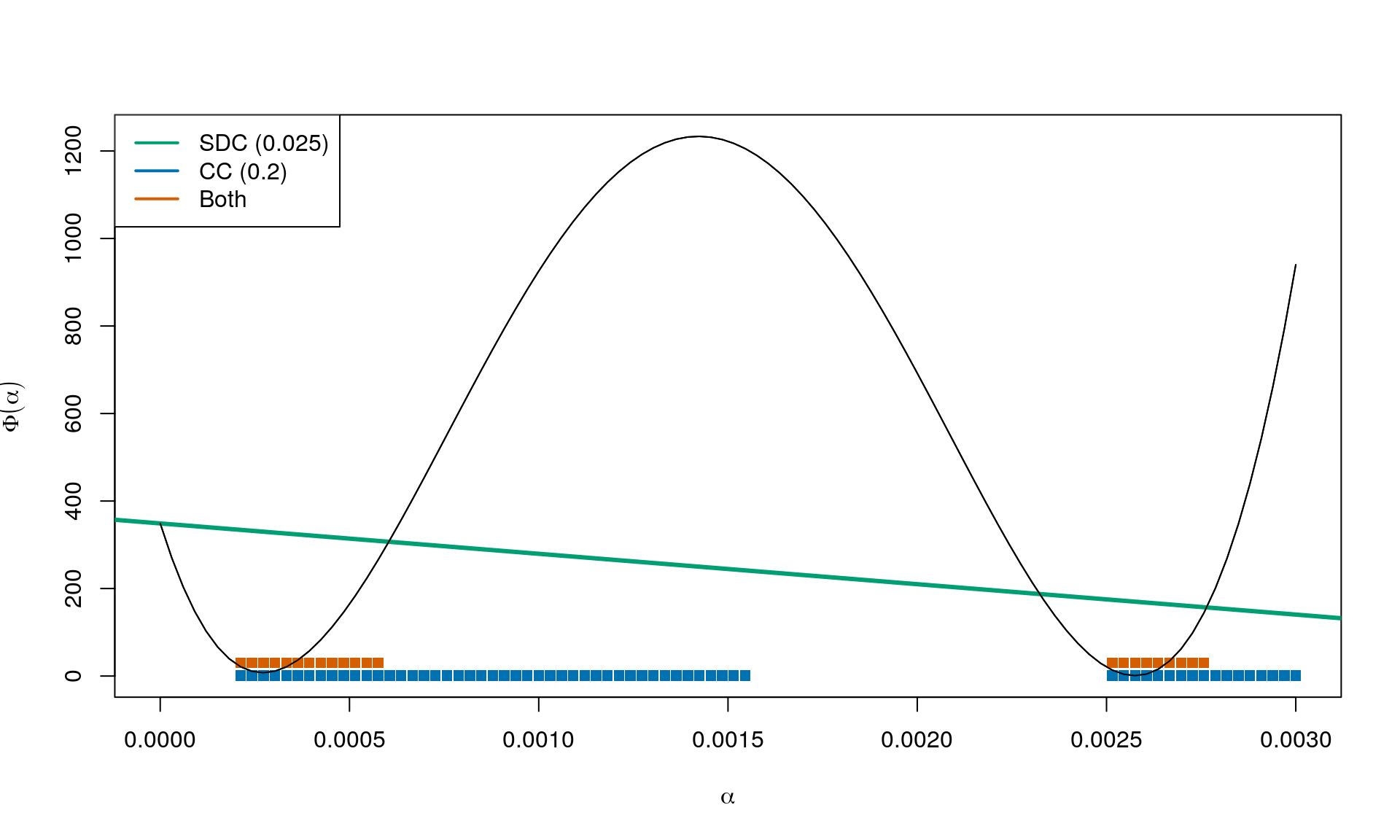
The strong Wolfe conditions
The curvature condition in the strong Wolfe conditions is:
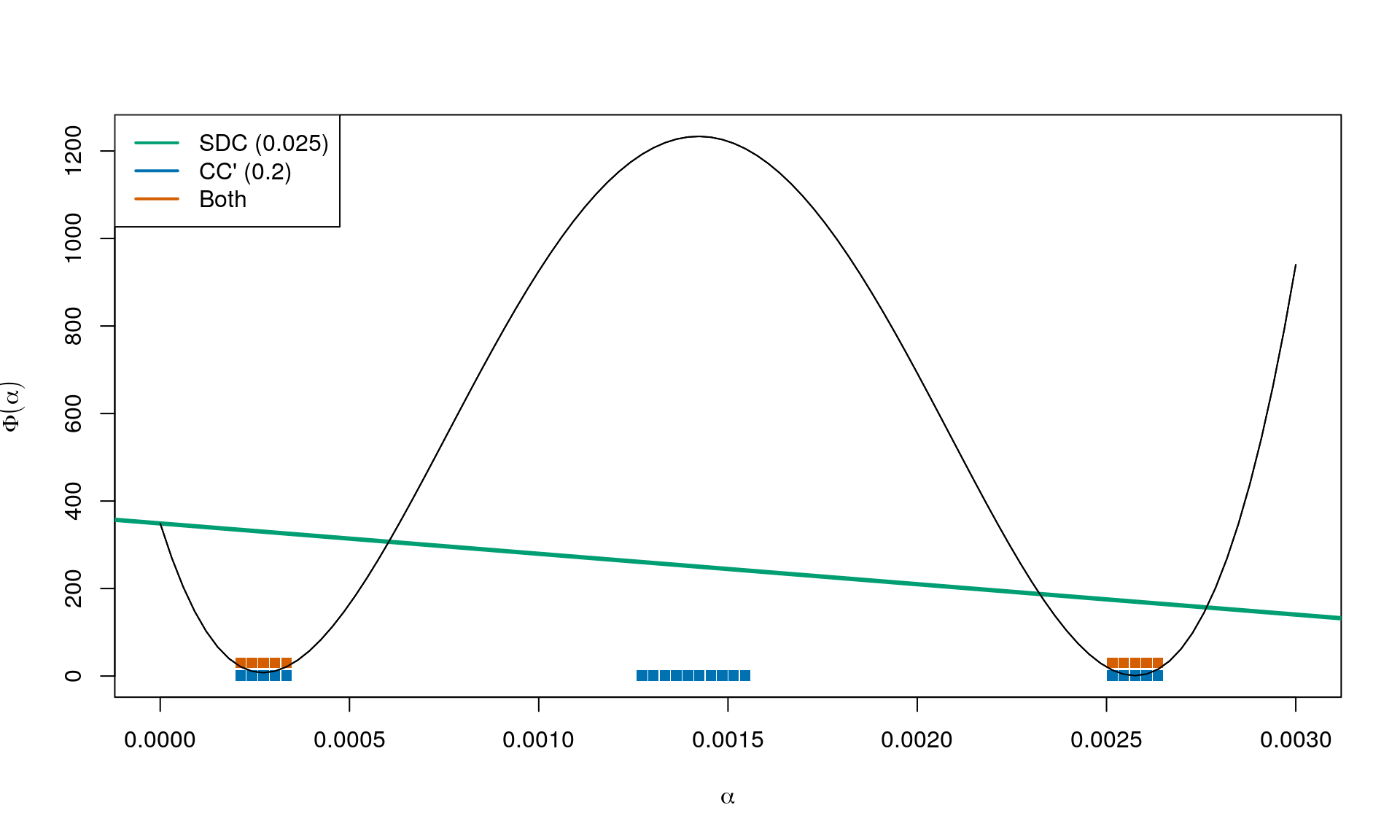
\[ |\nabla f(z_k + \alpha_k p_k)^\intercal p_k| \leq c_2 |\nabla f_k^\intercal p_k| \tag{CC'} . \]
This is very similar to CC, except now the directional derivative at the next iterate continuing in the same direction as got us here cannot be too positive.
Again combining with \(c_1 = 0.025\) and \(c_2 = 0.2\) we obtain:
Summary
Small values of \(c_1\) (close to 0) means that we can go far (limited almost only by a horizontal line). Large values of \(c_2\) (close to 1) means that the directional derivative in the next iterate can be almost as negative as it currently is.