Der er stor interesse i politiske meningsmålinger, specielt op til et folketingsvalg. De får stor opmærksomhed og medierne er ikke sene til at komme med store overskrifter, ofte baseret på et noget usikkert grundlag.
Jeg er interesseret i statistik og naturligvis også til dels i meningsmålinger. Når man sædvanligvis laver statistik er ønskescenariet, at man har en repræsentativ stikprøve fra populationen og vil bruge denne stikprøve til at udtale sig om hele populationen. Ved meningsmålinger opfylder en ideel stikprøve bl.a., at deltagere skal være tilfældigt udvalgt, at de udvalgte rent faktisk deltager og at de svarer retvisende. Mange af disse antagelser er ikke opfyldte i meningsmålinger, og det er medvirkende til at en stor usikkerhed – større end hvis stikprøven havde været ideel. Der er et hav af måder at forsøge at indsamle en repræsentativ stikprøve – eller i det mindste en stikprøve hvor man kan sige noget om afvigelserne og på den måde få styr på usikkerheden.
Overordnet set betyder det, at meningsmålinger er svære at have med at gøre, og man skal lave flere korrektioner for at forsøge at kunne udtale sig om den såkaldte statistiske usikkerhed. Og det er altså bare ekstremt svært.
(Indsat 28. juni 2019:) Claus Thorn Ekstrøm har skrevet et fremragende indlæg om meningsmålinger på sandsynligvis.dk, hvor der også findes mange andre interessante indlæg.
Udover meningsmålinger er der på valgaftenener også prognoser (startende med exit poll kl. 20:00). De er også interessante, men ikke helt så meget som meningsmålinger. De er dog på mange måder lettere at håndtere, fordi prognoser bygger på faktisk optalte stemmer.
Jeg vil forsøge at kigge nærmere på disse prognoser. I dette indlæg vil jeg kigge nærmere på prognoserne for Folketingsvalget i 2019.
Det ideelle ville være at have datastrømmen fra aftenen, således man havde den rækkefølge afstemningsområderne blev optalt og indrapporteret i. Det arbejder jeg på at få, men jeg ved endnu ikke om det kan lade sig gøre.
Jeg har dog fået god hjælp fra DR, der har udleveret informationer om deres prognoser i løbet af aftenen til mig. Tak for det. TV2 har jeg desværre ikke været i stand til at få data fra, så det har jeg kun 2 prognoser med i løbet fra i løbet af aftenen (ved 27,9% og 84,4% optalt). Udover DR’s prognoser, bruger jeg DR’s og TV2’s exit polls samt valgdata fra https://kmdvalg.dk, der består af de endelige optællinger.
Folketingsvalget 2019
Først sammenlignes resultatet med exit polls:
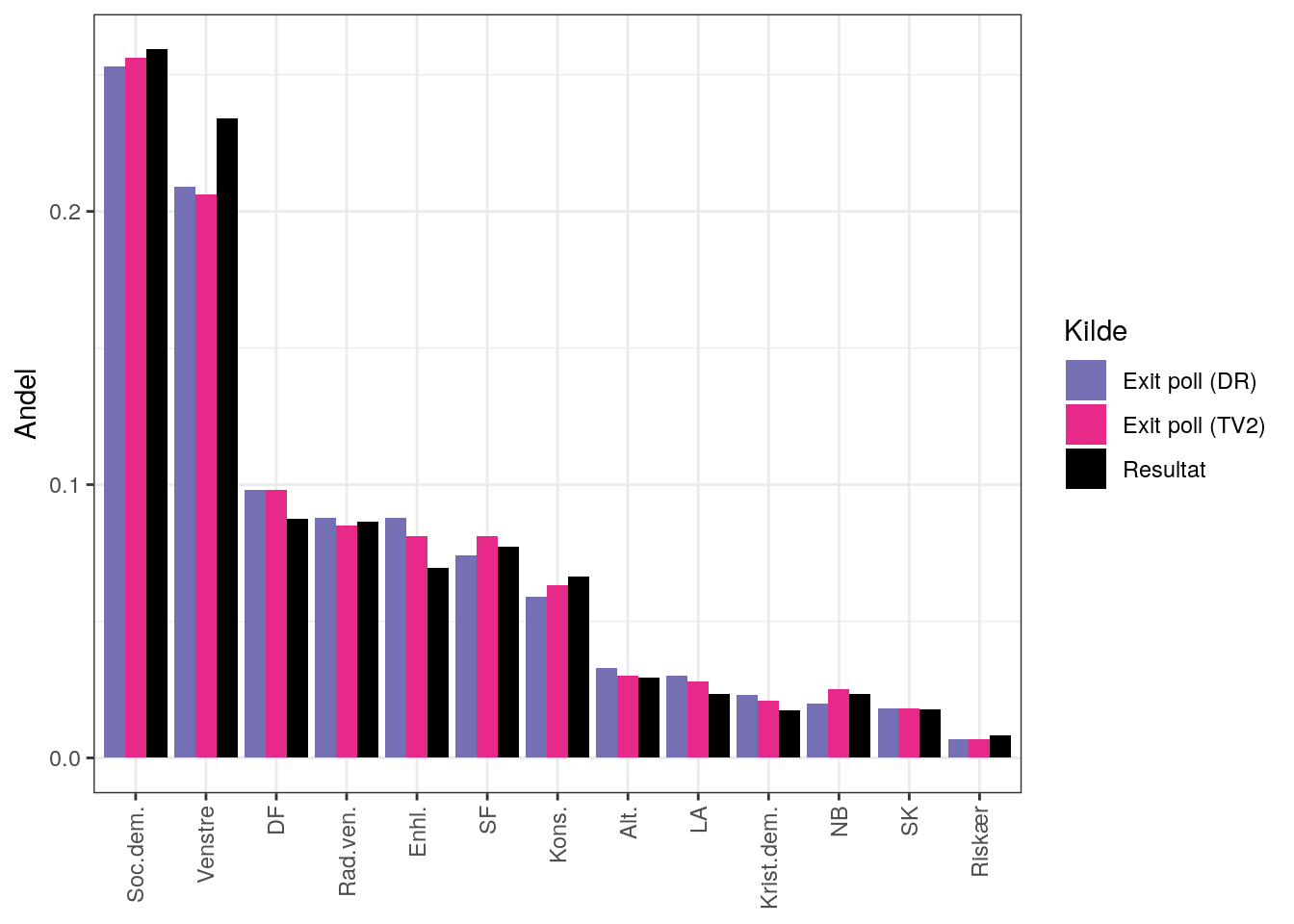
Som man kan se, er der generelt en fin overensstemmelse. Forskellene ser ud til at være størst for Venstre, DF og Enhedslisten.
Der er mange måder at måle afvigelser på. I statistik benytter man ofte \[ (\text{observeret} - \text{forudsagt})^2, \] \[ \left | \text{observeret} - \text{forudsagt} \right | , \] \[ \text{observeret} - \text{forudsagt} , \] \[ \frac{\text{observeret} - \text{forudsagt}}{\text{observeret}} , \] eller \[ \left | \frac{\text{observeret} - \text{forudsagt}}{\text{observeret}} \right | , \] men der er mange flere at vælge imellem. Der er fordele og ulemper ved metoderne (fx statistiske egenskaber, fortolkning), og ofte viser de konkordante resultater.
Her vælger jeg at anvende \(\text{observeret} - \text{forudsagt}\), som i dette tilfælde svarer til \[ \text{resultat} - \text{exit poll} . \] Med andre ord er det afvigelsen i procentpoint inkl. fortegn. Det har nogle ulemper i nogle sammenhænge (fx at hvis man laver gennemsnit kan man få en lav værdi uden at de enkelte bidrag nødvendigvis er små; hvis bare de har modsat fortegn), men fordelen er her at den er let at forstå og man får fortegnet med: Positiv værdi betyder at resultatet er højere end exit poll, og dermed har exit poll estimeret for lavt. Og omvendt ved negativ værdi. Og en værdi på 0 betyder at exit poll ramte resultatet. Jeg skalerer også fejlen så den største fejl i absolut værdi er 1. Man kan så illustrere disse fejl:
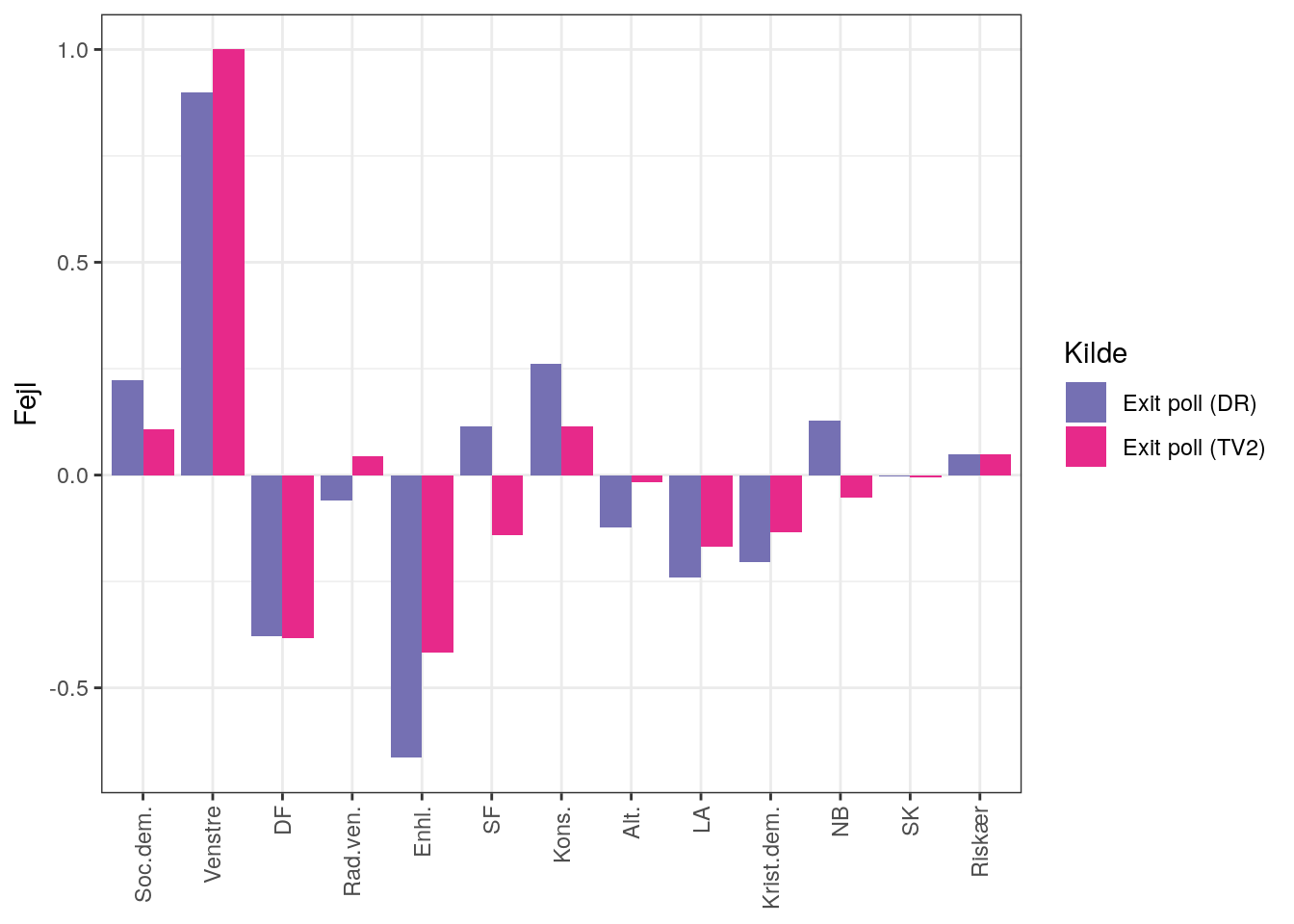
Vi kan nu visualisere hvordan prognoserne går fra exit polls imod resultatet som andelen af optalte går mod 1.
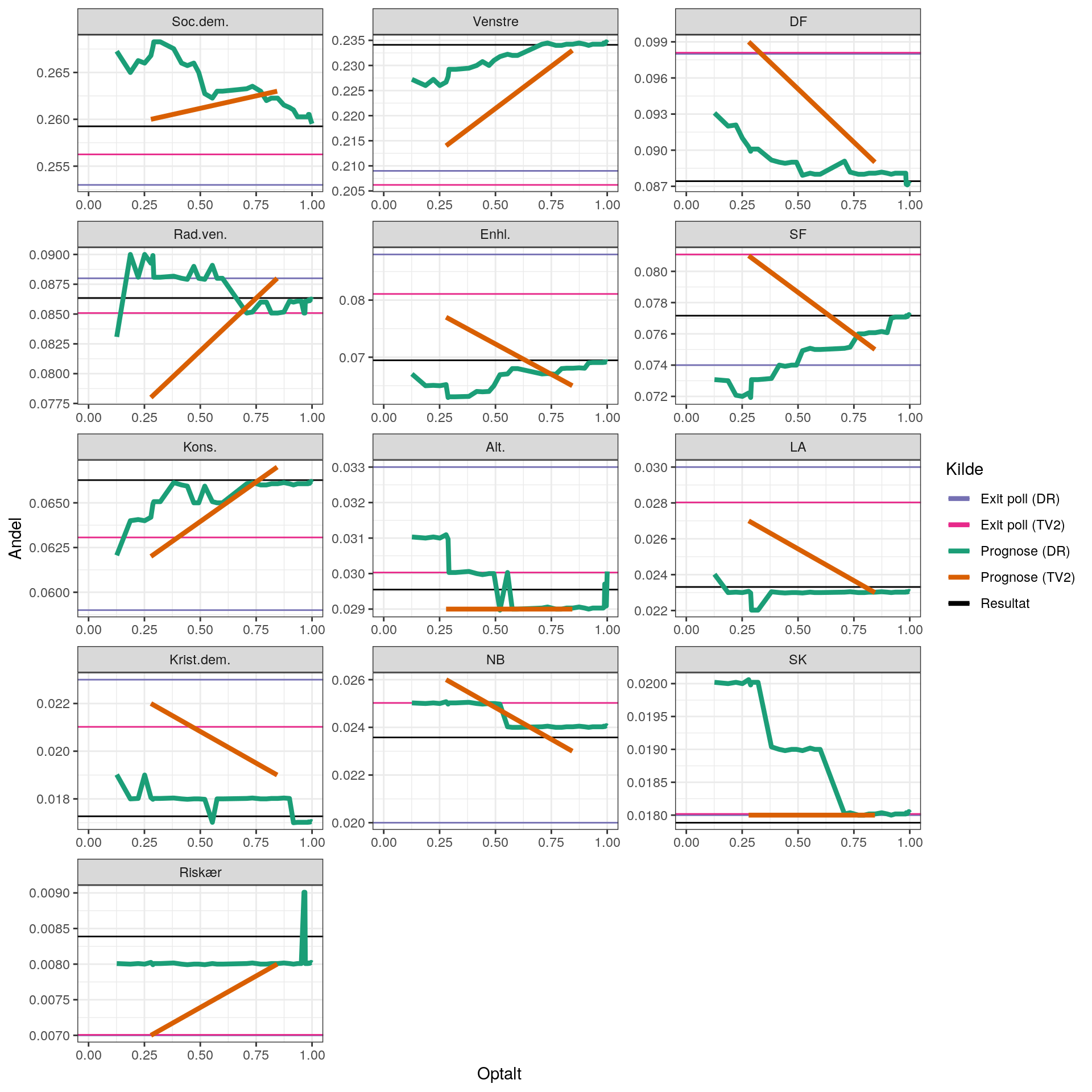
På samme måde som før kan vi i stedet betragte fejlen (igen indekseret så den største er 1):
Bedre prognoser?
Hvad sker der hvis man helt simpelt laver sin egen prognose, der er baseret på de optalte stemmer?
Jeg har desværre ikke pt. oplysninger om rækkefølgen som resultaterne ankom i (det håber jeg at kunne skaffe), så jeg er nødt til at simulere en række mulige rækkefølger.
Der er mange strategier til det. Eksempelvis vil valgsteder med få stemmer nok blive talt op først.
Jeg laver to modeller:
- Steder med få stemmer har større sandsynlighed for at blive talt op først
- Alle steder har lige stor sandsynlighed for at blive talt op på et givent tidspunkt
Derudover holder jeg det simpelt. Jeg betragter også kun prognoser for 10%, 20% osv. op til 100%.
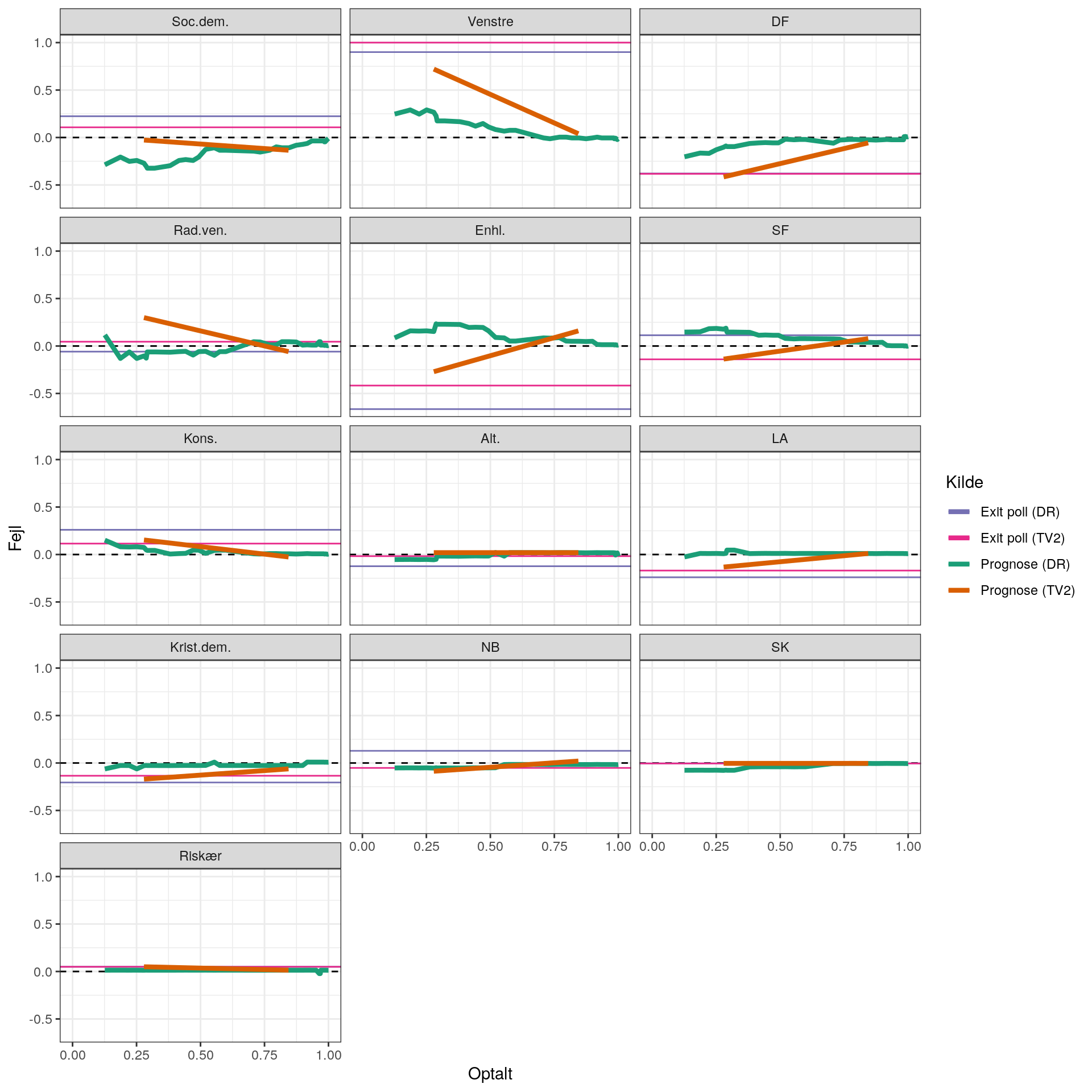
På samme måde som før kan vi i stedet betragte fejlen (igen indekseret så den største er 1):
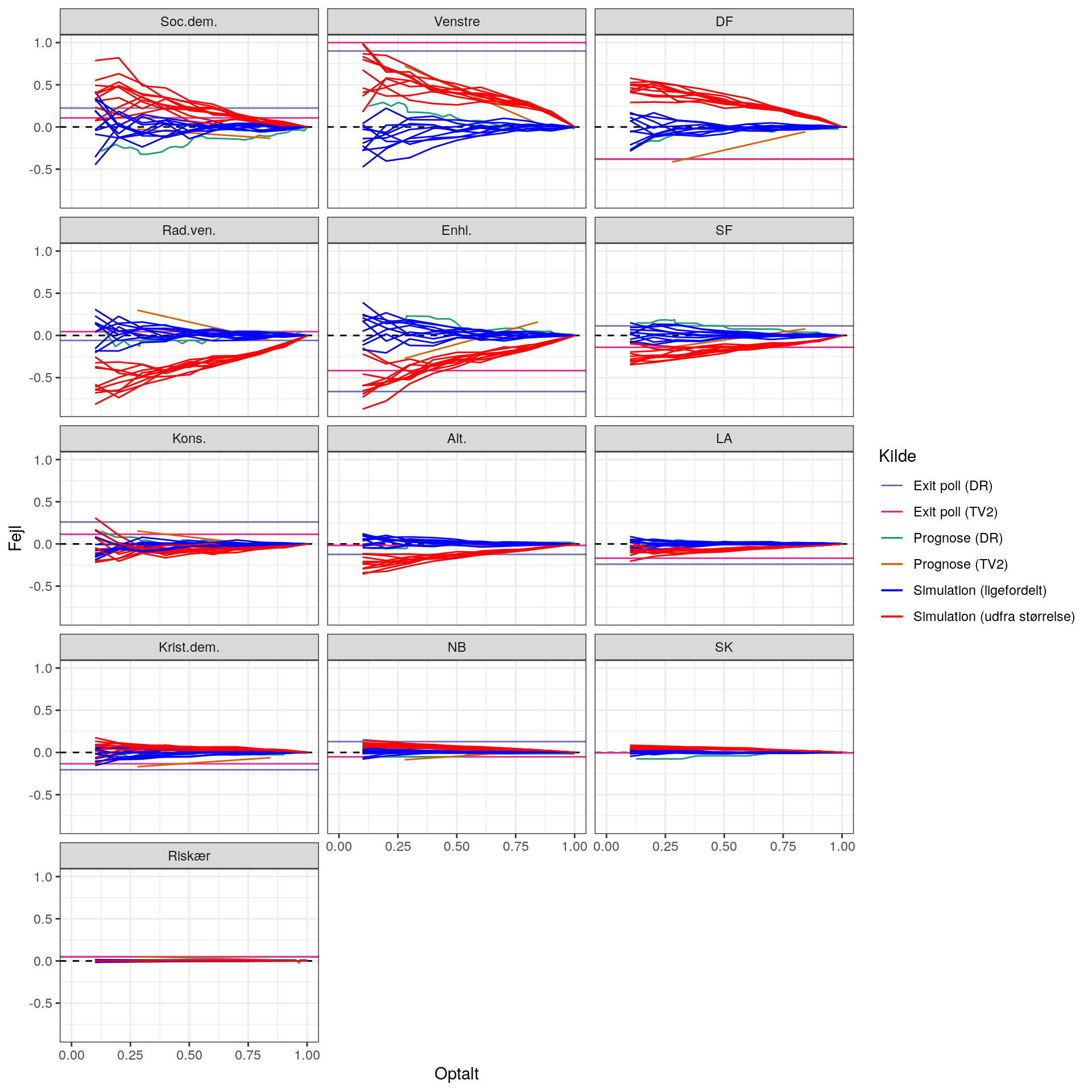
Lad os prøve at kigge nærmere på prognoserne for færre partier:
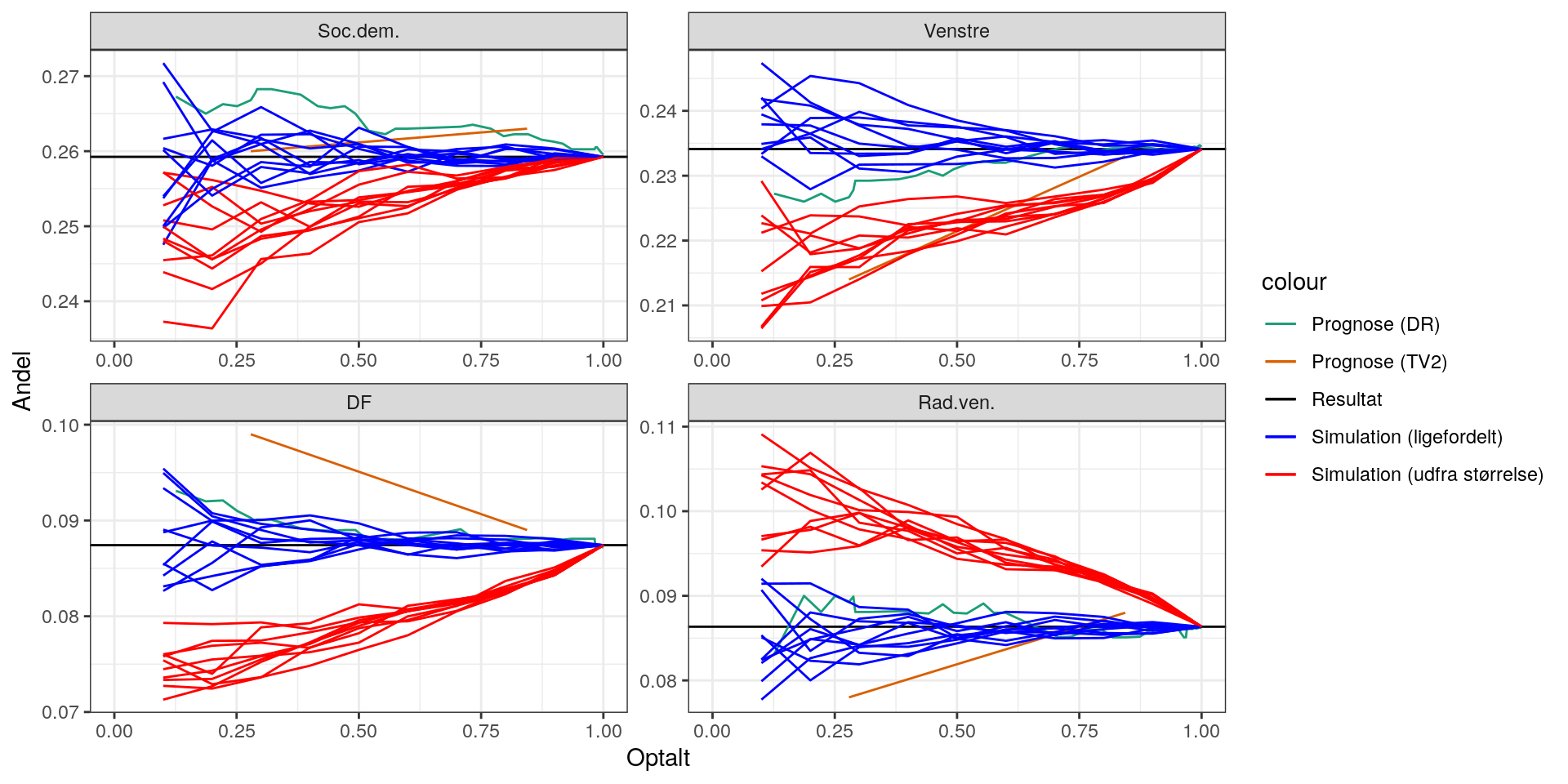
Man kan altså se, at hvis man kunne få resultaterne ind tilfældigt (uanset størrelse), så ville det være lettere at lave prognoser. Man kan også se, at hvis man fx lægger systematik ind og får resultater fra mindre steder først, giver det anledning til systematiske fejl.
Der er altså sandsynligvis noget at komme efter hvis man laver en model, der inkorporerer noget om afstemningsstederne i modellen. Det kunne være størrelsen. Men det kunne også være andre ting som fx andre afstemningssteder de plejer at ligne (man kunne fx kigge på data fra både 2015 og 2019).